
エンジニアのエンジニアによるエンジニアのためのサイト
News
07/25 おすすめ情報に 『 【案件】Azure AD関連の認証設計/azureの基本設計 』 を追加しました。

十二回目の投稿です。今回の内容は、PostgreSQLにおけるVACUUM処理に関するものです。
参画中の案件では、業務サービスが使用するデータベースソフトのリプレイスが行われており、
リプレイス後はPostgreSQLをベースとしたデータベースソフトにて業務サービスを展開して
いく予定となっています。直近の業務にて、リプレイス後に使用予定のデータベースソフトや
PostgreSQLに関する調査を行う機会があり、その際に学んだPostgreSQLのVACUUM処理に
ついて共有します。
◆ PostgreSQLにおける不要領域
VACUUM処理について説明する前に、PostgreSQLにおける不要領域について紹介しておきます。
PostgreSQLでは、あるレコードをDELETEで削除しても、そのレコードのデータはディスクから
削除されません(削除フラグ的なものを削除対象のレコードに付与し、そのレコードを参照しない
ようにしているだけ)。同様に、あるレコードをUPDATEしても、更新前のデータはディスクに残り
続ける挙動となっています。このように、使用されなくなったデータが存在するディスク領域の
ことを、本投稿では不要領域と呼びます。使用されないにもかかわらずディスクに残り続けるため、
不要領域がパフォーマンスの低下につながることがあります。このようなパフォーマンス低下を
改善する機能が、今回紹介するVACUUM処理です。
◆ VACUUM処理の概要
それではPostgreSQLにおけるVACUUM処理について説明します。VACUUMとは、不要領域を再利用
可能にする、すなわち、使用されなくなったデータが残る領域を別のデータが使用できる状態に
する機能のことです。ただし、これは不要領域を空き領域に変換してOSに返す(ディスク容量を
増やして、別のソフトウェアからも利用できるようにする)ということではありません。不要
領域を空き領域に変換して再利用可能な状態にしたい場合は、VACUUMに「FULL」という
オプションを指定します(VACUUM FULL処理)。VACUUMはデータベースのパフォーマンス改善の
ための機能ですが、その名称はデータベース製品によって異なります。VACUUM処理によるデータ
ベースのパフォーマンス変化などについては、次節にて検証します。
◆ VACUUM処理の挙動確認
本節では、VACUUM処理を手動で実行し、それによる性能変化などについて確認してみます。
【手順】
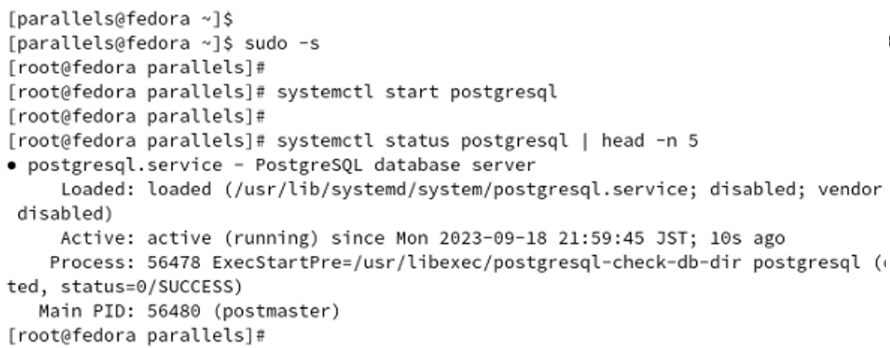
[1] PostgreSQLサービスの開始
rootシェルを起動し、PostgreSQLサービスを開始します。既に開始済みであれば、この手順は
スキップできます。必要に応じて、「systemctl status」コマンドにて、「active(running)」と
表示されること、すなわちサービスが稼働中であることを確認します。
$ sudo -s
# systemctl start portgresql
# systemctl status postgresql
[2] AUTOVACUUM機能の無効化
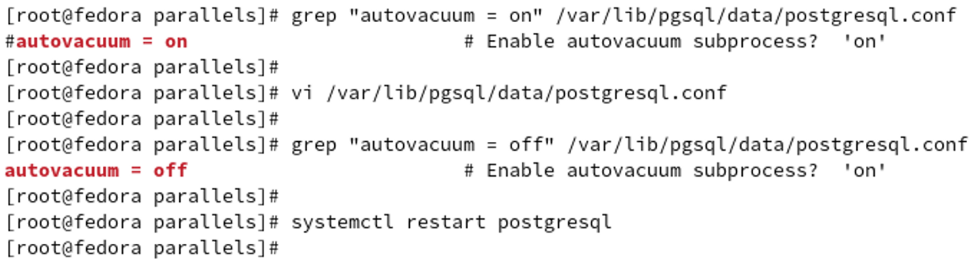
VACUUMを自動で実行するAUTOVACUUMという機能があります。今回は簡単のため、この機能を
無効化しておきます。無効化するためには、PostgreSQLの設定ファイル「postgresql.conf」内の
パラメータ「autovacuum」にて「off」を指定(行頭に「#」がある場合は外す)し、PostgreSQL
サービスを再起動します。下図では、「postgresql.conf」の編集前後で「autovacuum」の値を
grepコマンドにて抽出し、値を書き換えたことを確認しています。
# vi /var/lib/pgsql/data/postgresql.conf
# systemctl restart postgresql
[3] 検証用データベースの作成
postgresql用のユーザ(ここでは「postgres」)にスイッチし、検証用のデータベース
「sample-db」を作成します。作成できれば、そのデータベースに接続します。接続後はユーザの
プロンプトにデータベース名が表示されます。
# su - postgres
# createdb sample-db
# psql -d sample-db

[4] AUTOVACUUMの適用状況の確認
[2]で無効化したAUTOVACUUMの適用状況を改めて確認します。「off」と表示されれば
AUTOVACUUMが正しく無効化できています。
sample-db=# SHOW autovacuum;

[5] 検証用テーブルの作成
検証用のテーブル「test_vacuum」を作成します。作成後は、データベース 「sample-db」に
対応するディレクトリ内にテーブル「test_vacuum」に対応するファイルが作成されるため、
そのファイル名を確認しておきます (この手順については参考1が詳しいです)。
sample-db# CREATE TABLE test_vacuum(id INTEGER, val TEXT);
sample-db# SELECT datid, datname FROM pg_stat_database WHERE datname = 'sample-db';
sample-db# SELECT relfilenode,relname FROM pg_class WHERE relname = 'test_vacuum';

上述のコマンドで得られたファイルを参照し、別のプロンプトからテーブル 「test_vacuum」の
サイズを確認します。レコードは0件であるため、サイズは 0バイトでした。
# ls -lh /var/lib/pgsql/data/base/16440/16441

[6] 検証用レコードの挿入
テーブル「test_vacuum」に対し、検証用のレコードを挿入します。詳細な説明は割愛しますが、
次のコマンドにて、「id」が連番で「val」が乱数のレコードが100万件挿入されます。
sample-db=# INSERT INTO test_vacuum(id, val) SELECT generate_series AS id, RANDOM() AS val FROM GENERATE_SERIES(1, 1000000);

再びテーブルのサイズを確認すると、51Mバイトへ増えたことが分かります。

[7] VACUUM処理前の確認①
レコードが100万件となったテーブル「test_vacuum」にて、SELECT文の処理を計測してみます。
PostgreSQLのプロンプトにて「\timing」と入力することで、 各SQL文の処理時間が計測できます
(計測を終了したい場合は再度「\timing」を 入力します)。
sample-db=# \timing

試しに「id」が「65535」のレコードを何度か検索してみると、概ね45~55ms前後の時間がかかる
ことが確認できました。
sample-db=# SELECT * FROM test_vacuum WHERE id = 65535;

[8] VACUUM処理前の確認②
レコードが100万件あるテーブル「test_vacuum」から、レコードを30万件削除し、再度SELECT
文の処理を計測してみます。なお、「id」が「0」または「600000」以下の偶数のものを削除
していますが、これに深い意図はありません(強いて言えば、不連続な不要領域が生まれると
考えたからですが、これについては未調査です)。
sample-db=# DELETE FROM test_vacuum WHERE MOD(id, 2) = 0 AND id < 600001;
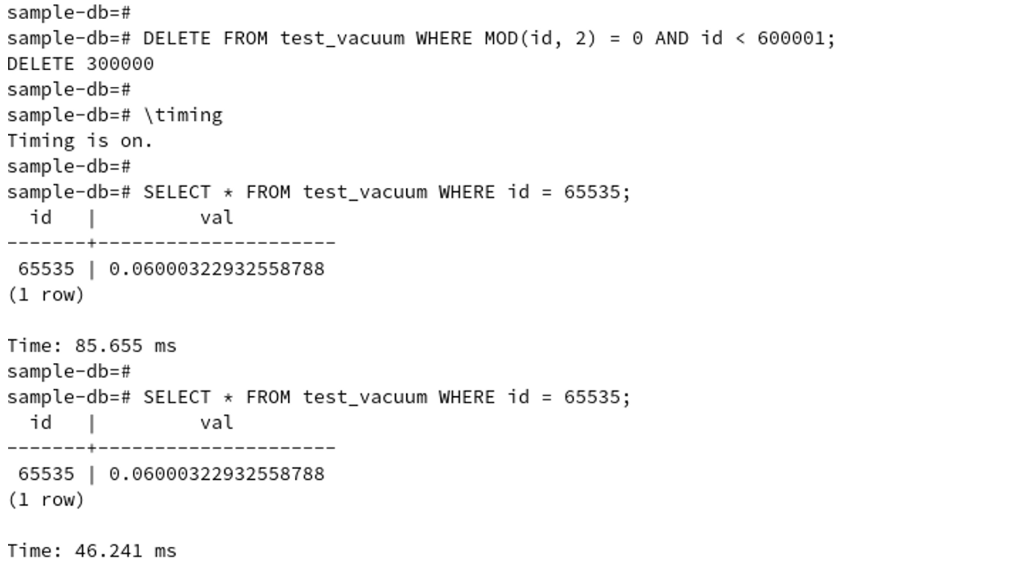
レコード削除直後の処理はやや遅くなりましたが、それ以降の処理は[7]の結果とほとんど変わり
ませんでした。また、データベースのサイズも51Mバイトのままであることが確認できます。

[9] VACUUM処理の実施と処理後の確認
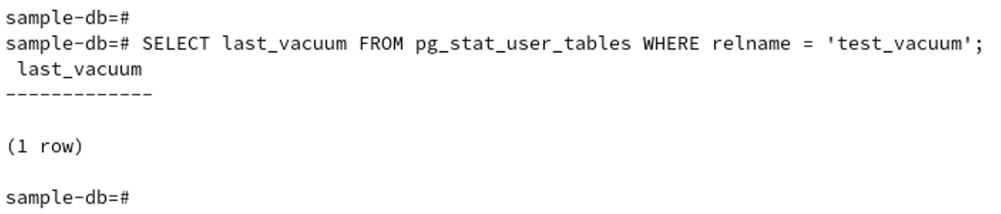
VACUUMを行い、処理速度などに変化が見られるかどうかを確認します。なお、 次のコマンドにて
最後にVACUUMを行った日時を取得できますが、現時点では結果は得られません(AUTOVACUUMを
無効化しているため)。
sample-db=# SELECT last_vacuum FROM pg_stat_user_tables WHERE relname = 'test_vacuum';
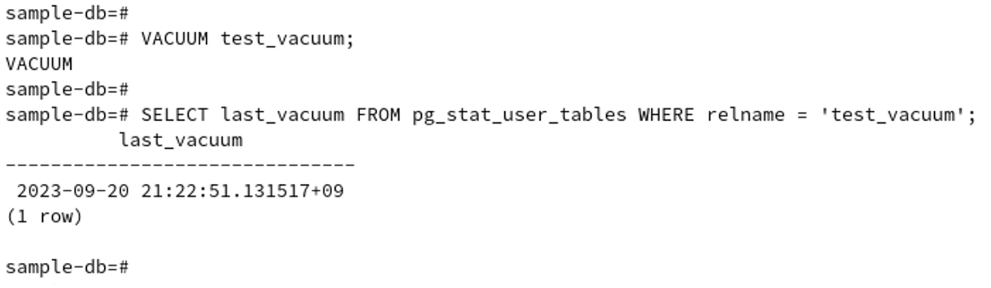
VACUUMは次のコマンドで実施できます。また、最後にVACUUMを行った日時が更新されたことも
確認しておきます。
sample-db=# VACUUM test_vacuum;
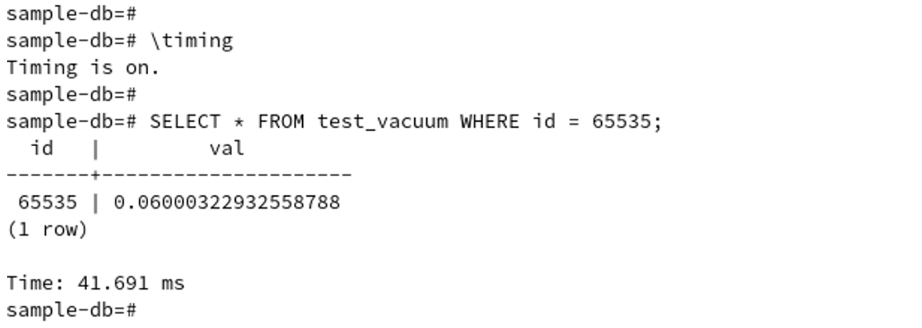
それではいよいよVACUUM後における処理の変化を確認します。処理速度が向上したかどうかは
なんとも言えないですが、今回の検証ではレコードの検索時間は概ね35~45msへと変化しました。
レコード数を増やしたり副問合せを含むような命令を計測したりすれば、処理速度の向上が明確に
確認できるかもしれません。
なお、VACUUMは不要領域を空き領域に変換してOSに返すわけではないため、データベースの
サイズは51MBのままであることが確認できます。

[10] 後処理
検証を終えたら、AUTOVACUUMを有効化しておきます。有効化するためには、PostgreSQLの設定
ファイル「postgresql.conf」内のパラメータ「autovacuum」 にて「on」を指定し、PostgreSQL
サービスを再起動します。また、必要に応じて PostgreSQLサービスを停止したり、検証用データ
ベース/テーブルを削除したりします。
◆ 感想など
データベースに関する書籍をいくつか読んだことがありますが、VACUUMなどのチューニング
機能について言及のあるものは読んだことがなかったため、今回の業務は非常にためになりました。
本投稿では扱っていませんが、VACUUMには問合せを最適化するようなオプションなどもあるため、
引き続きVACUUMに対する理解を深めていきたいと思います。
◆ 参考
記事内にて言及していないものもありますが、全体的に以下を参考にしました。
・【参考1】https://www.techscore.com/blog/2018/12/18/postgresql-vacuumで年末大掃除/
・【参考2】https://postgresweb.com/post-5194
・【参考3】https://tech-blog.rakus.co.jp/entry/20221227/vacuum
・【参考4】https://www.postgresql.jp/docs/12/routine-vacuuming.html
・【参考5】https://qiita.com/mkyz08/items/ffc34c13510bd1c5adb1
以上です。





